mongodb 常用语法 |
您所在的位置:网站首页 › yzh 是什么意思 › mongodb 常用语法 |
mongodb 常用语法
|
docker安装mongo:https://blog.csdn.net/m0_37606574/article/details/111128197 语法参考:https://www.yiibai.com/mongodb/mongodb_quick_guide.html 登录 第1个mongo参数:表示访问名为mongo的容器mongo admin:表示在容器内部访问mongo,登录用户admin $ docker exec -it mongo mongo admin 其效果等同于 $ docker exec -it mongo /bin/bash $ mongo admin 输入用户密码注意:用户登录数据库后。先切换到admin库,输入密码登录 > db #要先用db命令查看所在库 admin > use admin #切换到admin库 switched to db admin > db.auth('admin', '123456') #验证密码,登录成功 1 创建新用户在admin库,创建用户:test/123456 > db.createUser({user: "test",pwd: "123456",roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]} ) 查看用户必须切换到admin库 > use admin switched to db admin > db.system.users.find() #查看用户 { "_id" : "admin.admin", "userId" : UUID("23d93dc6-83c9-475f-9625-80e87d33c2c3"), "user" : "admin", "db" : "admin", "credentials" : { "SCRAM-SHA-1" : { "iterationCount" : 10000, "salt" : "+p1+CTap78fBsFld1qepaQ==", "storedKey" : "IpEy0UpqrtIASDS3lC/HHTvuOzY=", "serverKey" : "xgdnlk7II/2ujrXwHYHInWo5miU=" }, "SCRAM-SHA-256" : { "iterationCount" : 15000, "salt" : "jVKPTiHw1CJjWb8v5EXjdeaOVfJLyJ4H4W6naA==", "storedKey" : "LcN+5DPc6NlrC8cUD2e20uZM4A+fvYVHK+Lz+i2TAF0=", "serverKey" : "39YEVKY2OWjA/W0d+TW7ZJ3sA3/WEFJN4VnxY1je/+s=" } }, "roles" : [ { "role" : "userAdminAnyDatabase", "db" : "admin" } ] } { "_id" : "test.test", "userId" : UUID("2c1d16b1-f23d-4a5b-ade6-2754a90dae96"), "user" : "test", "db" : "test", "credentials" : { "SCRAM-SHA-1" : { "iterationCount" : 10000, "salt" : "dBM0lzlgn+Z6B+8qJnAoeg==", "storedKey" : "NBFktpZ74R5KfQGq0P0XL3RpXSc=", "serverKey" : "Twx+cSGPesZH51zhB9z8nmkM5Aw=" }, "SCRAM-SHA-256" : { "iterationCount" : 15000, "salt" : "j9qgYy66wZPljV0xK3OeeorntcR6eq+sVDPAsQ==", "storedKey" : "OJhoKwocQ31ASSpgeX5pQkOdpwNQcMVpAhWvbydDZ3o=", "serverKey" : "66wZo4A3+BFpmuNokN71PbIkBknJn/G9nesYsJUvY9M=" } }, "roles" : [ { "role" : "userAdminAnyDatabase", "db" : "admin" } ] } 删除用户说明:删除用户的时候需要切换到用户管理的数据库才可以删除 > use admin switched to db admin > db.dropUser("test") #在admin库删除test用户失败 false > use test switched to db test > db.dropUser("test") #切换到test库,删除test用户才成功 true 新建测试用户jpjinga,给mydb库验证了删除用户后,我为mydb库,新建一个jpjinga用户。 > db.createUser({user: "jpjinga", pwd: "123456", roles: [{ role: "dbOwner", db: "mydb" }]}) Successfully added user: { "user" : "jpjinga", "roles" : [ { "role" : "dbOwner", "db" : "mydb" } ] } 切换登录用户jpjinga踩到个坑,耽误了半天: 新建的用户jpjinga,登录输入密码死活验证不成功,切到mydb库下插入文本的时候又提示我没有权限,需要登录。 解决方案: 新建用户jpjinga,登录后的实际位置在jpjinga库下(虽然我并没有创建)。用 db 命令可以看到切到admin库下,输入密码登录才能成功。登录成功后,再切到自己的库mydb下才有权限操作。 $ docker exec -it mongo mongo jpjinga # 重新用test用户登录 > db # 查看所处位置 jpjinga > use admin # 切换的admin库 switched to db admin > db.auth('jpjinga','123456') # 登录密码验证 1 > use mydb # 现在再切到自己的库 switched to db mydb语法 如果想创建一个数据库名称为 , 那么 use DATABASE 语句应该如下: > use mydb switched to db mydb要检查当前选择的数据库使用命令 db > db mydb如果想查询数据库列表,那么使用命令 show dbs. > show dbs admin 0.000GB config 0.000GB local 0.000GB所创建的数据库(mydb)不存在于列表中。要显示的数据库,需要至少插入一个文档进去。 > db.movie.insert({"name":"my test!"}) > show dbs local 0.78125GB mydb 0.23012GB test 0.23012GBMongoDB的默认数据库是test。 如果没有创建任何数据库,那么集合将被保存在测试数据库。 现在就可以看到自己的库了 > show dbs mydb 0.000GB删除数据库 MongoDB db.dropDatabase() 命令用于删除现有的数据库。 如果想删除新的数据库 , 那么 dropDatabase() 命令将如下所示: > use mydb switched to db mydb > db.dropDatabase() # 删除mydb库 >{ "dropped" : "mydb", "ok" : 1 } > db # 查看所处位置,还是在mydb库下 mydb > show dbs # 查看数据库,列表已经空了,mydb库下的数据已经被删除了 >管理集合Collection 我认为可以把集合理解成“表” > db.createCollection('myc') # 新建集合myc { "ok" : 1 } > show collections # 展示集合 movie myc > db.myc.insert({"age":"12"}) # myc是我们的集合名称,如果集合不存在于数据库中,那么MongoDB创建此集合,然后插入文档进去。 WriteResult({ "nInserted" : 1 }) > db.myc.drop() # 删除集合 true > show collections movie查询文档 要从集合查询MongoDB数据,需要用find()。基本语法如下: > db.COLLECTION_NAME.find()或者格式化输出结果 > db.COLLECTION_NAME.find().pretty()测试find()方法 # 插入数据 > db.c1.insert({"name": "jjp", "age": 50, sex: "M"}) > db.c1.insert({"name": "yy", "age": 12, sex: "M"}) > db.c1.insert({"name": "pp", "age": 32, sex: "F"}) > db.c1.find() # 查询 { "_id" : ObjectId("5fd5fcf1aa13aa8810f809ef"), "name" : "jjp", "age" : 50, "sex" : "M" } { "_id" : ObjectId("5fd5fcf8aa13aa8810f809f0"), "name" : "yy", "age" : 12, "sex" : "M" } { "_id" : ObjectId("5fd5fcfdaa13aa8810f809f1"), "name" : "pp", "age" : 32, "sex" : "F" }除了find()方法还有findOne()方法,仅返回一个文档。 RDBMS Where子句等效于MongoDB 条件查询: 注意:如果用大小去比较时,该字段必须为数字类型,不能是数字的自符串。字符串的数字比大小查询不到 操作语法示例RDBMS等效语句Equality{:}db.mycol.find({"by":"yiibai tutorials"}).pretty()where by = 'yiibai tutorials'Less Than{:{$lt:}}db.mycol.find({"likes":{$lt:50}}).pretty()where likes < 50Less Than Equals{:{$lte:}}db.mycol.find({"likes":{$lte:50}}).pretty()where likes 50Greater Than Equals{:{$gte:}}db.mycol.find({"likes":{$gte:50}}).pretty()where likes >= 50Not Equals{:{$ne:}}db.mycol.find({"likes":{$ne:50}}).pretty()where likes != 50继续测试条件查询 # 查询所有name=jjp的数据 > db.c1.find({"name":"jjp"}) { "_id" : ObjectId("5fd5fcf1aa13aa8810f809ef"), "name" : "jjp", "age" : 50, "sex" : "M" } # 查询 age < 50,age字段必须是数字类型,不能是字符串 > db.c1.find({"age":{$lt:50}}) { "_id" : ObjectId("5fd5fcf8aa13aa8810f809f0"), "name" : "yy", "age" : 12, "sex" : "M" } { "_id" : ObjectId("5fd5fcfdaa13aa8810f809f1"), "name" : "pp", "age" : 32, "sex" : "F" } # 查询 age db.c1.find({"age":{$lte:50}}) { "_id" : ObjectId("5fd5fcf1aa13aa8810f809ef"), "name" : "jjp", "age" : 50, "sex" : "M" } { "_id" : ObjectId("5fd5fcf8aa13aa8810f809f0"), "name" : "yy", "age" : 12, "sex" : "M" } { "_id" : ObjectId("5fd5fcfdaa13aa8810f809f1"), "name" : "pp", "age" : 32, "sex" : "F" } and 多条件查询 > db.c1.find({"name":"jjp", "sex":"M"}).pretty() { "_id" : ObjectId("5fd5fcf1aa13aa8810f809ef"), "name" : "jjp", "age" : 50, "sex" : "M" }上面给出的例子相当于where子句:where name = 'jjp' and sex = 'M'。可以传递任何数目的键-值对在find子句。 or 条件查询 > db.c1.find({$or: [{"name":"jjp", "age":50}, {"name":"pp"}]}).pretty() { "_id" : ObjectId("5fd5fcf1aa13aa8810f809ef"), "name" : "jjp", "age" : 50, "sex" : "M" } { "_id" : ObjectId("5fd5fcfdaa13aa8810f809f1"), "name" : "pp", "age" : 32, "sex" : "F" } 上面给出的例子相当于where子句:where (name = 'jjp' and age = 50) or name= 'pp' 使用 and 和 or 组合使用 > db.c1.find({"sex":"M", $or: [{"name":"jjp"}, {"name":"pp"}]}).pretty() { "_id" : ObjectId("5fd5fcf1aa13aa8810f809ef"), "name" : "jjp", "age" : 50, "sex" : "M" } 上面给出的例子相当于where子句:where sex = 'M' and(name = 'jjp' or name= 'pp') 更新文档 MongoDB的update()和save()方法用于更新文档到一个集合。 update():将现有的文档中的值更新save():使用传递到save()方法的文档替换现有的文档 # 将name='jjp'的数据,修改为:age=17, sex = 'WM' > db.c1.update({"name":"jjp"}, {$set:{"age":18, "sex":"WM"}}) WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 查询结果 > db.c1.find({"name":"jjp"}) { "_id" : ObjectId("5fd5fcf1aa13aa8810f809ef"), "name" : "jjp", "age" : 18, "sex" : "WM" }上面给出的例子相当于:update db.c1 set age = 18, sex = 'WM' where name = 'jjp'; 验证update 默认情况下,MongoDB将只更新单条文档。如需更新多条,需要设置参数 'multi' 为 true。 db.c1.update({"name":"jjp"}, {$set:{"age":44, "sex":"SS"}}, {multi:true})验证update单条、多条
验证save save方法,以文档_id作为条件,用传入save方法的文档全量覆盖原文档
删除文档 如下:将删除c1集合中,所有name='jjp' 的文档 db.c1.remove({"name":"jjp"})
如果只想删除1条 db.c1.remove({"name":"jjp"}, 1)
MongoDB投影(即约定展示列的字段) mongodb投影意义是只选择需要的数据,而不是选择整个一个文档的数据。如果一个文档有5个字段,只需要显示3个,只从中选择3个字段。MongoDB的find()方法,解释了MongoDB中查询文档接收的第二个可选的参数是要检索的字段列表。在MongoDB中,当执行find()方法,那么它会显示一个文档的所有字段。要限制这一点,需要设置字段列表值为1或0。1是用来显示字段,而0被用来隐藏字段。
总结:find({}, {})方法可以传递2个参数。第1个参数传递查询条件,第2个参数限制展示字段(可缺省) 限制文档(即约定展示结果条数,可用来分页) limit()方法的基本语法如下 > db.COLLECTION_NAME.find().limit(NUMBER)案例:限制查询结果条数,可用来分页
skip() 方法:跳过查询结果中的前n条 > db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER) #当前查询结果,跳过前N条。默认跳过0条
文档排序 要排序MongoDB中的文档,需要使用 sort()方法。 sort() 方法接受一个包含字段列表以及排序顺序的文档。 要使用1和-1指定排序顺序。1用于升序,而-1是用于降序。 语法sort()方法的基本语法如下: > db.COLLECTION_NAME.find().sort({KEY:1})验证
MongoDB索引 索引支持查询高效率执行。如果没有索引,MongoDB必须扫描集合中的每一个文档,然后选择那些符合查询语句的文档。若需要 mongod 来处理大量数据,扫描是非常低效的。 索引是特殊的数据结构,存储在一个易于设置遍历形式的数据的一小部分。索引存储在索引中指定特定字段的值或一组字段,并排序字段的值。 要创建索引,需要使用MongoDB的ensureIndex()方法。 语法ensureIndex()方法的基本语法如下 > db.COLLECTION_NAME.ensureIndex({KEY:1})这里键是要创建索引字段,1是按名称升序排序。若以按降序创建索引,需要使用 -1. 例子 > db.c1.ensureIndex({"name": 1}) { "createdCollectionAutomatically" : false, "numIndexesBefore" : 2, "numIndexesAfter" : 3, "ok" : 1 } 在 ensureIndex()方法,可以通过多个字段,来创建多个字段索引。 > db.c1.ensureIndex({"name": 1, "age": -1}) { "createdCollectionAutomatically" : false, "numIndexesBefore" : 1, "numIndexesAfter" : 2, "ok" : 1 }ensureIndex() 方法还接受选项列表(这是可选),其列表如下: 参数类型描述backgroundBoolean构建索引在后台以便建立索引不阻止其它数据库活动。指定true时建立在后台。缺省值是false.uniqueBoolean创建一个唯一的索引,以使集合将不接受插入的的文档,其中的索引关键字或键匹配索引的现有值。指定true以创建唯一索引。缺省值是 false.namestring索引的名称。如果未指定,MongoDB通过连接索引的字段和排序顺序的名称生成一个索引名。dropDupsBoolean创建一个字段唯一索引时可能会有重复。MongoDB索引键仅第一次出现,并从集合中删除包含该键后续出现的所有文档。指定true以创建唯一索引。缺省值是 false.sparseBoolean如果为true,索引只引用与指定的字段的文档。这些索引使用更少的空间,但在某些情况下表现不同(特别是排序)。缺省值是 false.expireAfterSecondsinteger指定的值,以秒为单位,作为一个TTL控制MongoDB保留在此集合文件多久。vindex version索引版本号。默认的索引版本取决于mongod创建索引时运行的版本。weightsdocument重量(weight )是一个数字,它是从1至99,999的数字,表示字段相对于其它索引字段在得分方面的意义。default_languagestring对于文本索引,并为词干分析器和标记生成器列表中的语言决定了停用词和规则。它的默认值: english.language_overridestring对于一个文本索引,包含在文档中指定字段的名称,语言来覆盖默认语言。它的默认值:language.这个参数项的用法和find类似。ensureIndex({}, {}),放到第2个json里。 添加索引我给c1集合设置唯一索引name:
失败了,因为已存在该name字段的重复数据。不允许给其设置唯一索引。
我继续测试:给name, age 字段设置成联合索引。就没数据的冲突了:
总结:和关系型数据库的索引使用效果没啥区别。 MongoDB 聚合函数 聚合操作处理数据记录并返回计算结果。从多个文档聚合分组操作数值,并可以执行多种对分组数据业务返回一个结果。 在SQL中的count(*),使用group by 与mongodb的聚合是等效的。 对于MongoDB的聚合,使用的是aggregate()方法。 语法aggregate()方法的基本语法如下 > db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION) 例子:按name分组,求c1集合中的总年龄sum(age) > db.c1.aggregate([{$group : {_id : "$name", num_tutorial : {$sum : "$age"}}}])还是用我们的c1集合测试。根据name分组,去查询总年龄:
用于上述用途将等效于sql查询: select name, sum(age) from c1 group by name。 注意:不允许在聚合函数aggregate()前加find(),你觉得这样是先查询一定结果。再对结果做分组处理。这样是不对的。
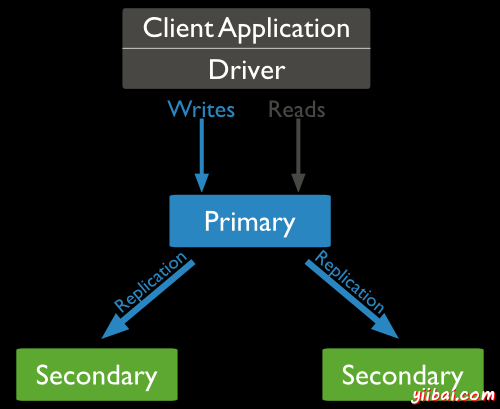
另外,在上述例子中,我们已经使用字段by_user进行分组并计算总和,也就是by_user 出现各个次数。一个列表中可用的聚集表达式。 表达式描述示例$sum从集合累加所有文档中的定义值db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}])$avg从集合中的所有文档计算所有给定值的平均值db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}])$min从集合中获取的所有文件的最小的相应值db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}])$max从集合中的所有文档中的相应值中获取最大值db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}])$push插入数组值到文档中db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}])$addToSet插入值所产生的数组到文档中,但不会产生重复db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}])$first从源文件获取根据分组的头文件。通常,这使得只能意会再加上一些以前应用“$sort” -stage db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}])$last从源文件获取根据分组的最后文件。通常,这使得只能意会再加上一些以前应用 “$sort”-stage.db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) MongoDB 搭建主从复制集群MongoDB通过使用副本集的复制来实现。副本集是一组承载同一个数据集的mongod实例。在副本的一个节点是接收所有的写操作主节点。所有的实例,次级,应用操作从主以便它们具有相同的数据集。副本集只能有一个主节点。 副本集是一组两个或更多个节点(通常至少3节点是必需的)。在副本集一个节点是主节点和其余的节点都是次要的。所有的数据复制是从主到次节点。在自动故障转移或维护时,选建立了主要和一个新的主节点被选择。故障节点的恢复后,再次加入副本集,并可以作为一个辅助节点。mongodb复制的典型图如下图,其中客户端应用程序总是与主节点和主节点交互,然后将数据复制到辅助节点。
副本集特征 N个节点的集群任何节点可为原发/主节点所有的写操作进入到主节点自动故障转移自动恢复协商一致选择主节点 建立一个副本集 // todo 可以百度一下docker搭建mongodb 的主从复制集群。懒得搞了,并不复杂。原理是他们的工作目录,都是用的同一个挂载卷。 MongoDB数据备份 语法 mongodump基本语法: mongodump -h 127.0.0.1 -p 27017 -u='jpjinga' -p='123456' --authenticationDatabase admin -d mydb -o /dump注意: --authenticationDatabase admin 表示登录用户必须先到admin库去认证,没有这个登录不成功。这个备份命令是在mongo容器内部执行的例子 # 首先进入mongo容器 docker exec -it mongo /bin/bash # 在容器的根目录,创建dump目录并进入 mkdir dump && cd dump # 执行备份 mongodump -h 127.0.0.1 -p 27017 -u='jpjinga' -p='123456' --authenticationDatabase admin -d mydb -o /dump效果
数据恢复 为了验证数据恢复,在操作之前,我们先删除`mydb`库
数据恢复语法: --authenticationDatabase admin:登录用户需要到admin库登录认证-d mydb:指定要恢复的数据库/dump/mydb:数据文件在容器内的位置 mongorestore -h 127.0.0.1:27017 -u='jpjinga' -p='123456' --authenticationDatabase admin -d mydb /dump/mydb效果
再次查询mydb 库下集合。数据已恢复:
当然,这里还要说明一下: 这个备份目录是在容器内部的。如果需要备份,需要从服务器目录挂载到这个备份目录,或者备份目录创建到挂载目录下。保证能把备份文件拿出来备份目录在容器启动前就可以挂载预留出来。 |
















【本文地址】
今日新闻 |
推荐新闻 |